Contextual Analysis of Emojis
For my CSCI 534 class, Affective Computing, I worked on a research project with four other master and PhD students. Our research question revolved around the usage of emojis in social media. It's a common preprocessing technique to strip emojis out of text prior to text analysis because their contributions are difficult to capture meaningfully. With a huge growth in social media platforms and users, emojis are being used more and more as direct ways to communicate, not just decorators of text. Messages are now sent with only emojis to get a point across, and they're usually understood by the recipient to the point of not requiring textual clarification. In order to fully capture the meaning of social media posts and conversations, we must find a way to meaningfully translate and understand emojis in the contexts they're being used.

A lot of existing work focuses on emojis in sentiment analysis which, while being an example of a meaningful representation, offers only a two dimensional look at how emojis are used to convey internal states of emotion and thought in the social media environment. Other research analyzes emojis in a more high-dimensional emotional space but limit the emojis studied. They also usually use the emotion categorization of the emoji to inform the context. We wanted to use an unsupervised approach to examine the opposite: what if we allowed the content and meaning of the text to inform the meaning of the emoji? Are there contextual clues we can uncover in text that would contribute to the understanding of the emoji being used? We used multiple methods to investigate these questions a little further and to gain insight into how emojis are being used in multiple different online interactions.
Methods
We decided to use a classical emotion model, Ekman's six basic emotion model, to define what emotions we wanted to try and capture in our analysis. We decided to use Twitter for the abundance of emojis used in communication, but also for the availability of data. We collected 83,000 tweets ranging from 2018 to 2020. We queried for 70 different emojis, with about 1000 - 1,200 tweets per emoji. We extract all the emojis from text and, using Ekman's six basic emotions, we pre-categorize all the emojis into emotion labels for later comparison in our contextual models.

Models and Results
We wanted to use a multitude of tools to try and capture the emotional context of emojis in the tweets we scraped. We used three main NLP methods: BERT, LDA, and LIWC.
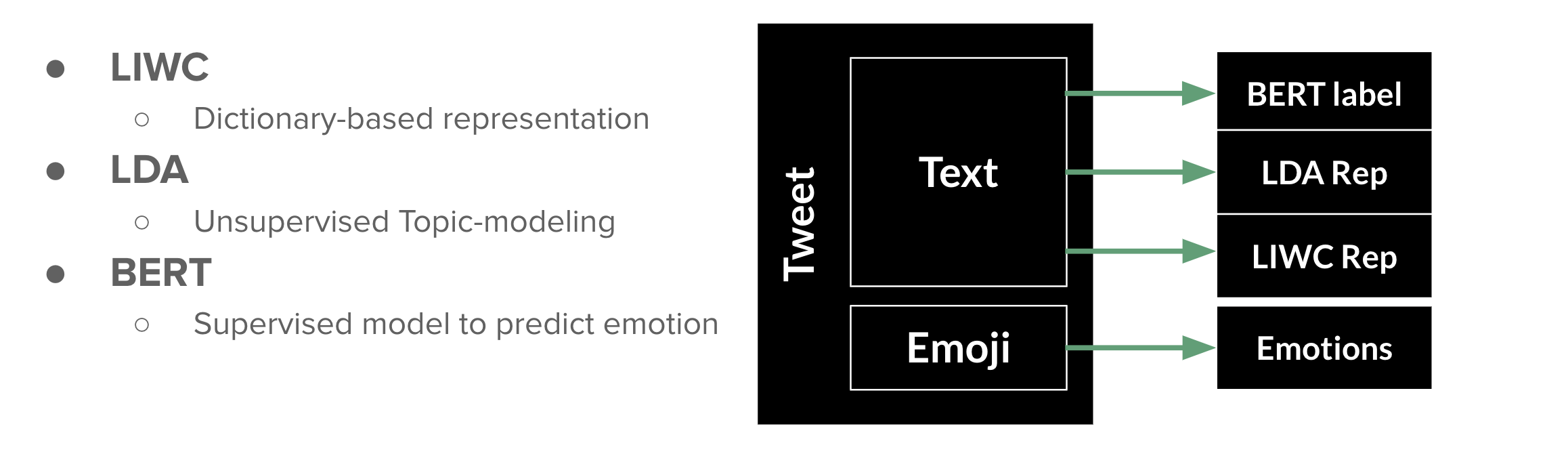
BERT
We used BERT, as outlined in the paper, Deep Bidirectional Transformers for Language Understanding, to predict emotion labels for tweets, which we then used to assign to the emojis present in said tweets. This allowed us to utilize the language present to inform the meaning of emojis, rather than the other way around, which is how emoji analysis is typically done. We used a dataset of tweets annotated for Ekman's emotions (Mohammad, 2017) and trained our BERT model to predict the emotion in our dataset. We then analyzed the way the pre-determined labels of our emojis compare to the emotion label assigned by BERT.


The results are shown above in these graphs of odds ratios. This basically shows that there are certain correlations and likelihoods between the pre-assigned emotion to an emoji and it's predicted emotion category based on the BERT model. For instance, we see that tweets predicted to have disgust as an emotion label, are more likely to contain emojis that are categorized as anger, disgust, and surprise. Another example, joy, shows that tweets labeled with this particular emotion, are more likely to contain emojis that are also labeled joy. Some of the more "complex" emotion labels like disgust or fear contain positive odds ratios with multiples emotions, maybe hinting at the multi-dimensionality of certain emotions.
LDA
Beyond emotion, we also wanted to examine the topics typically associated with each emoji. It's no secret that certain emojis are more used in certain contexts, and we wanted to try and capture that very different, but meaningful representation in our work. LDA is a topic-modeling technique that infers topics and assigns a probability distribution to each tweet and maps it to the topics inferred.

The results from the LDA analysis are shown in the graph above. It's a little messy, which could be due to a variety of factors, but within the noise we can see some patterns emerge that make some sense. When looking at the fifth row of topics, the one that starts with "day", we see that joy is the most likely emotion associated with this row. Looking at it more closely, it feels quite intuitive! Topics that are in this row include "happy", "best", "birthday", "home", and "god". It's not unreasonable to think that these topics occur with higher probability with the emotion joy. The last row is also interesting to look at, with the dominant emotion being surprise, we see words like "wait" or "lol" present, which could point to certain colloquial trends that correlate with surprise in social media.
LIWC
Another way we chose to analyze the context surrounding the usage of emojis was by utilizing a dictionary-based feature extraction technique that looks at different psycho-linguistic and social constructs, called Linguistic Inquiry Word Count (LIWC). There are different top-level categories that are in LIWC, and specific words that are associated with each category. We chose the following categories to use in our analysis: Affective, Social, Cognitive, and Biological Processes. We used regular expressions to match the words that were designated into each of those categories to the words in each tweet, and acquired a total word count for each. We then got the loadings and coefficients for each emotion.


The results for the LIWC model were some of the most surprising and informative. We can see for certain emotions, some psychological and social trends come to light. For instance, disgust, has the following LIWC sub-categories as the most predictive: Biological Processes, Health, Ingestion, and Sexual. It's very plausible to think that tweets and texts related to those topics could be deemed as "disgust". Another cool example, the words Causasion, Differentiation, and Insight are some of the words that lead to a higher probability of the text being classified as surprise. It was really interesting to see what categories of the human experience informed certain emotions, and what was even cooler about this analysis was that it was done during the COVID-19 pandemic. A little less than half of our tweets were scraped at the beginning of the pandemic, so it was notable to see some of these strong correlations for negative emotions like fear, anger, or disgust. It was a huge reminder that human interaction greatly reflects what is salient in our day-to-day life. This third additional analysis rounded out our chosen methods for trying to gauge the context of the tweets we collected, and how these contexts all tie in to the emojis people use to enrich and extend their communication.
Additional Thoughts
Overall, I really loved working on this project. It was short-lived and it was conducted during a really tumultuous time, but not only was it an incredibly collaborative project, it was a project that highlighted everyone's interests, strengths, and differences. Just on our team alone, we had a computer scientist who knew the ins and outs of full-stack development, we had an NLP/CS researcher, a cognitive scientist/computer scientist, and two people who regularly worked on robotics and hardware. Despite the craziness of the second half of our semester, everyone was super present all the time and offered to help out whenever someone needed it. Everyone contributed a significant amount and it was truly beautiful watching everyone work hard to get it done.
I really love the work from both a technical and social standpoint as well. Technically, we used a lot of different NLP methods and frameworks to do our analysis. From using more traditional approaches, especially in the social NLP world, like LIWC and LDA, to using state-of-the-art NLP models, like BERT, we utilized all kinds of methods to really extend our perspective on the contexts present in our dataset. We also used and tried out many different python packages to do the scraping and tried a bunch of different queries to get an equal distribution of tweets per emoji. From a social and psycho-linguistic aspect, we worked hard to address what we thought was a gap in our current understanding of how emojis interact with text, emotions, and communication. We recognize, as personal users of social media and texting platforms, the power that emojis have in contributing to human interaction, and we wanted to attempt to capture that power in a meaningful way. Is our research perfect? Absolutely not. Was it something that we found to be impactful? One hundred percent. Despite the flaws, I truly believe that the research presented here is a great step forward towards capturing the nuances in social media interaction and modern-day communication, in an extensive and comprehensive way.
One of the most important things to know about me is that I live for collaboration and this project exemplified the beauty of interdisciplinary participation and cooperation. Without everyone's perspective, there's no way that this project would've been completed. It really highlights the importance of surrounding yourself with smart, but different people. The paper can be downloaded here and our final presentation for our Affective Computing class can be found here.